

How we shrunk our Javascript monorepo git size by 94%
This isn't click bait. We really did this! We work in a very large Javascript monorepo at Microsoft we colloquially call 1JS. It's large not only in terms of GB, but also in terms of sheer volume of code and contributions. We recently crossed the 1,000 monthly active users mark, about 2,500 packages, and ~20million lines of code! The most recent clone I did of the repo clocked in at an astonishing 178GB.

For many reasons, that's just too big, we have folks in Europe that can't even clone the repo due to it's size.
The question is, how did this even happen?!
Lesson #1
When I first joined the repo a few years ago, I noticed after a few months that it was growing, when I first cloned it was a gig or 2, but after a few months was already at around 4gb. It was hard to know exactly why.
Back then I ran a tool called git-sizer , and it told me a few things about some blobs that were large. Large blobs happens when someone accidentally checks in some binary, so, not much you can do there other than enforce size limits on check ins which is a feature of Azure DevOps. Retroactively, once the file is there though, it's semi stuck in history.
Secondly, it flagged me about our Beachball change files, which we weren't deleting. We use them in the same way that Changesets work, accomplishing similar goals as semantic-release where we want to tell the packages how to automatically bump their semver ranges.
At times we'd get to 40k of them in a single folder, which we found out causes a large tree object to be created every time you add a new file into that folder.

So, lesson #1 we learned was...
Don't keep thousands of things in a single folder.
We ended up implementing two things to help here. One was a pull request into beachball which did several changes in a single change file instead of one per package.
Second, we wrote a pipeline which runs and automatically cleans up that change folder periodically to stop it from getting so large.
Huzzah! We fixed git bloat!
Lesson #2

Our versioning flow at scale maintains a mirror of main called versioned which stores the actual versions of packages so we can keep main free of git conflicts, and have an accurate view of which git commits correspond to which semver versions we release via NPM packages. (this needs another blog post, but I digress...)
I noticed that the versioned branch seeming to get harder and harder to clone because it kept getting so huge. But, we'd dealt with the change file issue, and the only thing going in that versioned branch in terms of commits was appends to CHANGELOG.md and CHANGELOG.json files.

Time passed on, and our repo, while growing slightly slower, still grew and grew. However, it was sort of difficult to know whether this growth was now due to simply scale, or something else altogether. We were adding hundreds of thousands of lines of code, and hundreds of developers every year since 2021, so a case was to be made that natural growth was occurring. However, once we came to realize that we had surpassed the growth rate of the one of the biggest monorepos at Microsoft, the Office one, we realized, something else must be wrong!
That's when we called for backup...

The author of such git features as git shallow checkout, git sparse index, and all kinds of other features created because of the size of our monorepos in Office, had just re-joined our organization after a stint at Github bringing those features to the world.
He took a look, and immediately realized something was definitely not right with this growth rate. When we pulled our versioned branches, those branches that only change CHANGELOG.md and CHANGELOG.json, we were fetching 125GB of extra git data?! HOW THO??
Welp, after some super deep git digging, it turned out that some old packing code checked in by Linux Torvalds (ever heard of him 🤷♂️) was actually only checking the last 16 characters of a filename when it gets ready to do compression of a file before it pushes the diffs. For context, usually git just pushes the diffs of changed files, however, because of this packing issue, git was comparing CHANGELOG.md files from two different packages! Stolee explains this well in here.
For example, if you changed repo/packages/foo/CHANGELOG.json, when git was getting ready to do the push, it was generating a diff against repo/packages/bar/CHANGELOG.json! This meant we were in many occasions just pushing the entire file again and again, which could be 10s of MBs per file in some cases, and you can imagine in a repo our size, how that would be a problem.
We were then able to try repacking our repo with a larger window git repack -adf --window=250 to have git do a better job compressing the pack files for our repo to reduce the size. This did definitely reduce the size of the repo significantly, however, we can do even better!
This PR https://github.com/git-for-windows/git/pull/5171 added a new way to pack the repo based upon walking git paths as opposed to the default of walking commits.
The results are staggering...
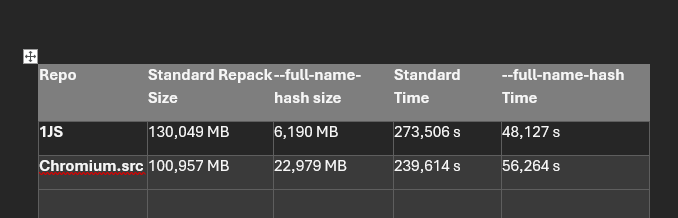
I ran a new git clone on my machine yesterday to try the new version of git in Microsoft's git fork (git version 2.47.0.vfs.0.2)...

And after running the new git repack -adf --path-walk ...
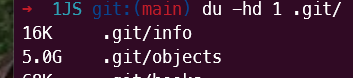
Crazy. It went from 178GB to 5GB. 😱

The other new configuration option being added will further ensure that the right types of deltas are generated at git push time...
git config --global pack.usePathWalk true
That will make sure your git push commands are performing the correct compression.
Any developer on the git version 2.47.0.vfs.0.2 can now repack the repo once cloned locally, as well as use the new git push path walk algorithm to stop the growth rate.
On Github, re-packing and git garbage collection happens periodically, but again, the type of packing which Github does will not correctly compute the deltas of these CHANGELOG.md and CHANGELOG.json files, or potentially any file that has the same 16+ character names which change a lot over time. Think i18n type of large string files and such.
Azure DevOps, which we're on, doesn't do any such re-packing, yet. So, we're working on getting that done as well so we can reduce the size of the repo on the server side as well.
Those changes will all make their way into the upstream of git as well! Hurray for OSS.
Wrap Up
If you work in a large-ish scale monorepo, and you have CHANGELOG.md or really any file that has a relatively long-ish name (>16 characters) which repeatedly gets updated, you may want to keep your eyes on this path walk stuff.
You can also try out thew new git survey command to see all kinds of new heuristics such as Top Files By Disk Size, Top Directories By Inflated Size, or Top Files By Inflated Size.
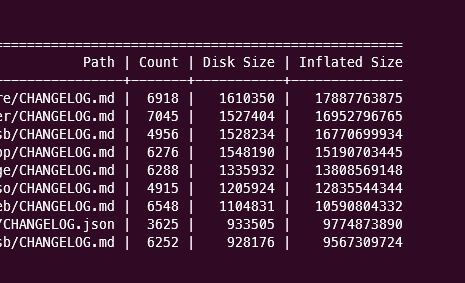
These heuristics will help give you a sense of whether the path walk work will affect your repo size too.
Overall I am so impressed and excited about our commitment to trying to produce solutions that help us scale repositories at Microsoft, but also take those solutions to the rest of the world..


